From Pipeline to Decision: How Investment Teams Run Diligence at Scale
Every investment decision starts the same way: a pipeline of targets and a folder of documents for each one. CIMs, financial statements, market reports, management decks. Before an analyst can form a single view, someone has to read all of it.
That reading is the bottleneck. Not the judgment, not the model, not the investment committee. The hours spent pulling the same handful of numbers out of the hundredth PDF this quarter, typing them into a spreadsheet, and hoping nothing was missed.
The work is repetitive, high-stakes, and done under a deadline. It's exactly the kind of work that should be automated, and exactly the kind that generic AI tools still get wrong.
Why Chatting With a PDF Doesn't Scale to a Pipeline
Most AI tools let you upload a document and ask questions. That's genuinely useful for a single target. But a deal pipeline isn't one document. It's fifty companies, each with its own stack of files, that all need to be evaluated the same way.
Do that in a chat window and the cracks show fast. You upload files one at a time. You retype the same prompt for every company. You copy answers into Excel by hand. And because each conversation is separate, there's no guarantee the AI applied the same logic to company nine that it applied to company one. By the time you've finished, you've done a new kind of manual data entry and you still can't fully trust the output.
Diligence needs consistency, structure, and an audit trail. Chat gives you none of the three.
Stage 1: Screening the Pipeline
The first job is triage. You have far more targets than you have time to study, and you need to get from a long list to a short one quickly without missing anything that matters.
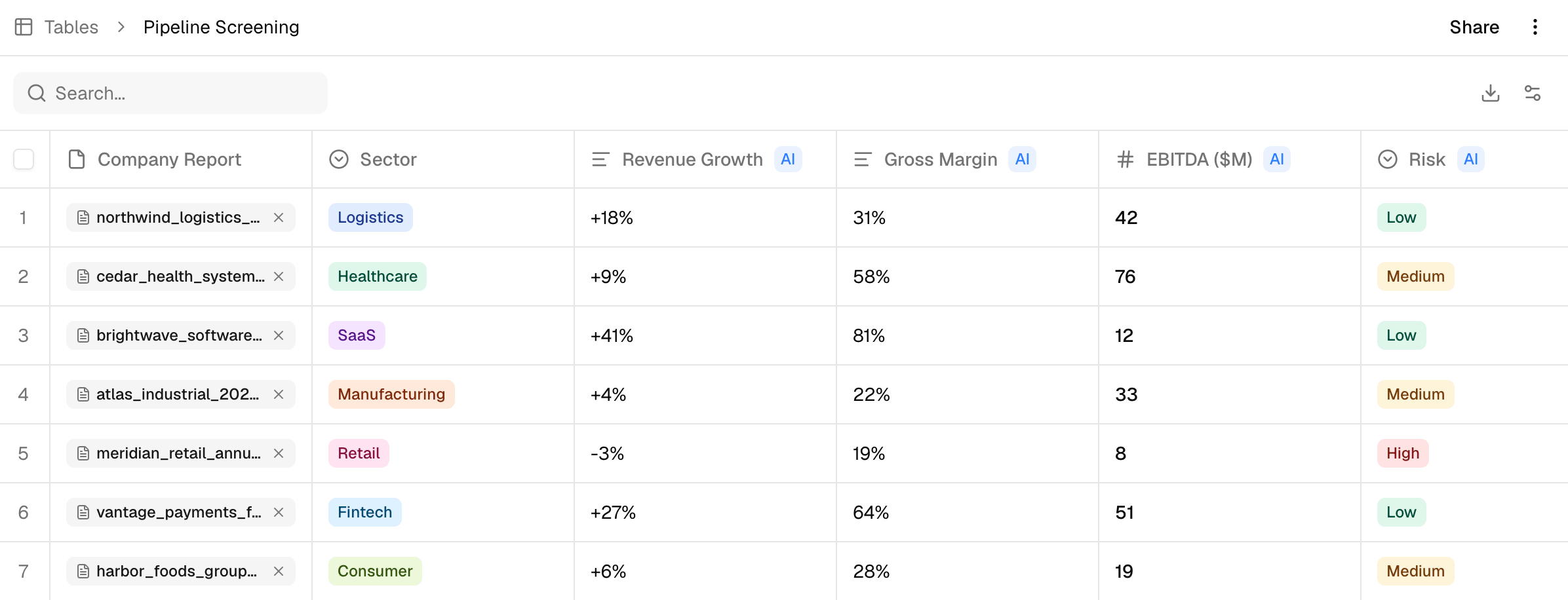
In Clavy, this is an agentic table. Each target is a row. Each thing you screen on is a column: revenue growth, gross margin, EBITDA, sector, headline risks. You define the columns once, point the table at your documents, and run.
Clavy dispatches agents across every row in parallel, filling the table while you do something else. A column can extract a number straight from a financial statement, classify a company into a sector, or flag a risk as Low, Medium, or High so you can sort on it later. Within minutes the entire pipeline is a structured, sortable dataset instead of a pile of folders.
Now the work that used to take a week happens in one pass. Sort by growth, filter out anything below your margin threshold, drop the targets in sectors you don't touch. The long list becomes a shortlist, and every company on it was evaluated by the same logic.
Stage 2: Diligence on the Shortlist
Screening tells you where to look. Diligence tells you what you're actually buying.
For the targets that survive, you go deep. Here the columns get more specific and more demanding: revenue by segment, contract terms, debt covenants, the top five customers and what share of revenue they represent, any accounting treatment that looks unusual. These aren't headline metrics. They're the details that decide whether a deal is what it appeared to be during screening.
Columns can also depend on each other. One column flags whether a company has meaningful customer concentration. The next reads only the flagged companies and explains the exposure in detail, pulling the specific names and figures from the documents. You're chaining reasoning across the dataset without wiring anything together by hand.
The output isn't a stack of summaries to read. It's a diligence grid you can take into an investment committee, filter live, and defend line by line.
A Number You Can't Defend Is Worthless
In finance, the answer is only half the job. You have to be able to show where it came from. An EBITDA figure with no source behind it is not a finding. It's a liability.
This is where most AI workflows quietly fall apart, and where Clavy is built differently. Every value in the table carries a reasoning trace: the steps the agent took, the documents it drew from, and the specific passages it used to reach the number. When the committee asks where the customer concentration figure came from, you don't go re-read the CIM. You open the trace, see the exact page, and move on.
That traceability is what makes the speed usable. Going faster only helps if you can still stand behind every output, and in diligence you have to stand behind all of them.
Where the Time Goes Instead
None of this removes the analyst. It moves them. The hours that used to go into extracting and re-keying data go into the part of the job that actually needs a person: weighing the risks, pressure-testing the thesis, deciding what the numbers mean.
Define the diligence once, run it across the whole pipeline, review the results with the sources one click away. That's the shift. Less reading, more deciding.
If your team spends more time pulling numbers out of documents than reasoning about them, this is what Clavy was built to fix.
Request a demo and run it against your own pipeline.
Have questions or feedback? Get in touch